Importance of the shape of the environment-demographic parameter relationships to understand the effects of environmental variability on population growth
by Judy Che-Castaldo on Oct 7, 2022(Blog post written by Christie Le Coeur, christielecoeur@gmail.com)
How do organisms cope with temporal fluctuations in their environment (for instance in weather conditions, food resources…)? In the context of climate change, where both the mean and the magnitude of fluctuations of numerous environmental drivers have been altered, this burning question has recently motivated extensive research in ecology and evolutionary biology, including our most recent work.
In a fluctuating environment, the ‘stochastic growth rate’ of a population indicates whether the population size is expected to grow, remain constant or decline in the long-term. The stochastic growth rate is directly driven by the mean values, the temporal variation and covariation of the demographic parameters, e.g., the survival probabilities and fertility coefficients at different ages or other life stages. The theory tells that a higher variability of demographic parameters will reduce the stochastic growth rate, especially when demographic parameters show positive covariation (i.e., when they increase or decrease together). By magnifying the temporal variability of the demographic parameters, an increase in environmental variability could then reduce the stochastic growth rate of populations, increasing their extinction risk. However, environmental variability may also lead to an increase of the stochastic growth rate, if the relationship between an environmental driver and some demographic parameters is convex (e.g., survival probability s1 in Fig. 1). Then, a favourable change in environmental conditions tends to increase the demographic parameters’ value more than an unfavourable change of similar magnitude decreases it, thereby increasing their mean. It is thus critically important to characterise explicit links between all demographic parameters and environmental drivers, in particular the curvature, to understand the potential effects of increased environmental variability on population growth.
Not all demographic parameters in a population show the same curvature (convex, concave, linear) or the same degree of lability in their response to environmental variability. Some demographic parameters may be selected to be more labile, meaning they fluctuate more freely with temporal variation in environmental conditions (through convex, linear or concave responses; e.g., s1 and s2, and fertility coefficient f3 in Fig. 1). Others are selected to be more buffered to variation, meaning they do not fluctuate much with the environment (flat relationships, e.g., s3 in Fig.1). Studying how organisms may combine such lability and buffering of their demographic parameters across life stages to enhance population growth is then crucial to understand how they adapt to live in varying environments.
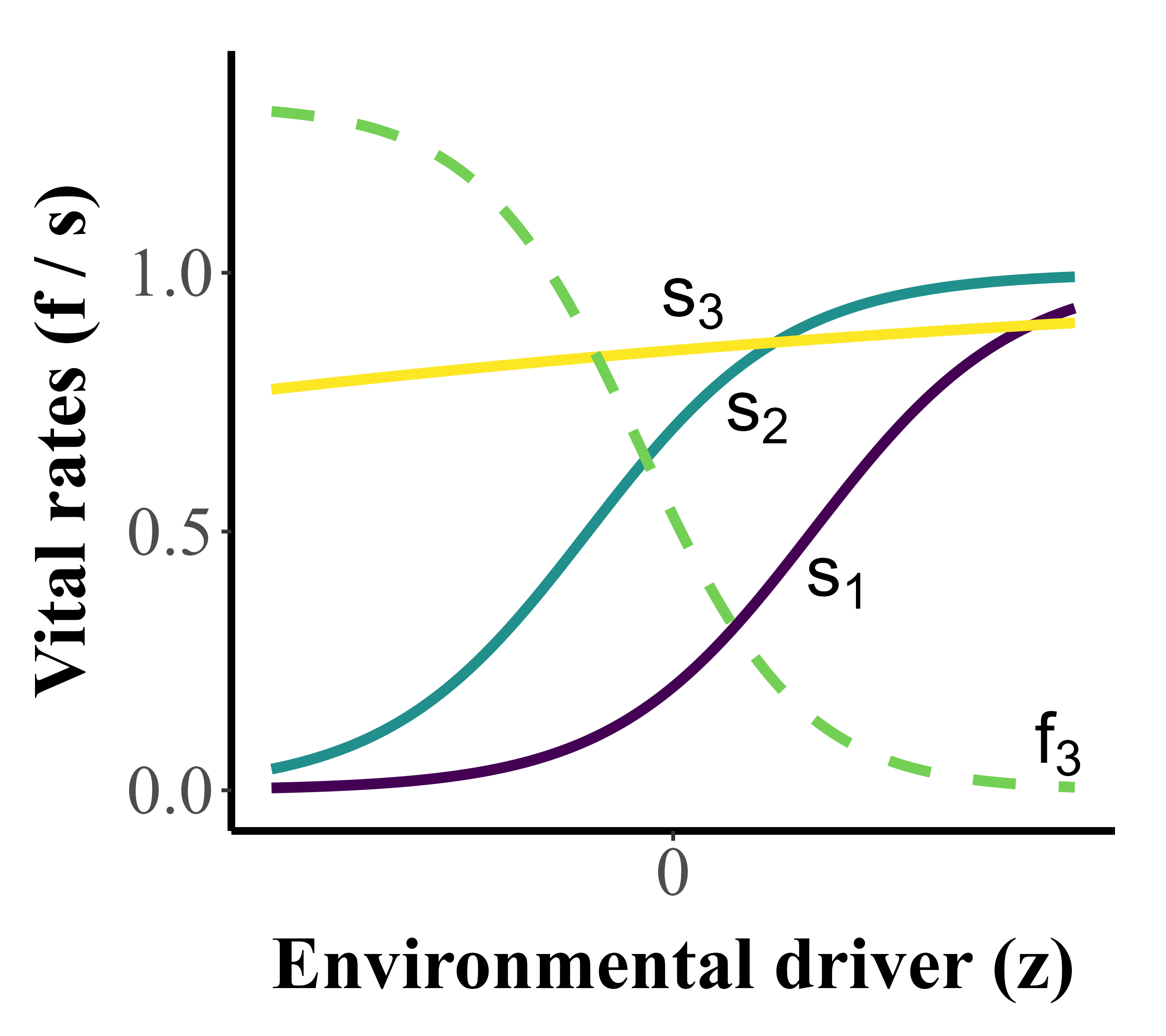
Figure 1 - Example of age-specific demographic responses to an environmental driver z (e.g. temperature, resource availability). s1, s2, s3= mean survival rate at age 1, 2 and 3, respectively; f3= Mean fertility at age 3 (mature individuals). s1 and s2 are labile and covary positively, while fertility and survival rates covary negatively with z. s3 is buffered against environmental variation.
In our research, we provide a method to study the combined effects of demographic buffering and lability on the stochastic growth rate ln(λs). We decompose ln(λs) into two components that capture the effects of environmental variability arising from nonlinearity (the ‘nonlinearity component’), and variation and covariation (the ‘variance-covariance component’) of all demographic parameters in response to a main environmental driver z. The nonlinearity component is positive (/negative, /null) if the overall response of the demographic parameters to environmental variability is convex (/concave, /linear). The variance-covariance component is close to zero when demographic parameters are mostly buffered, and increase negatively with increased variation of, and positive covariation among parameters. Consequently, positive effects of environmental variability on ln(λs) can only be observed when the benefits of lability through convex responses (positive nonlinearity component) outweigh the negative effects of the variation and covariation of the demographic parameters (negative variance-covariance component).
We then explored theoretically when labile demographic responses to environmental variability can lead to positive ln(λs) across generation time. To do so, we extracted 154 (st)age-structured matrix population models from COMADRE Animal Matrix Database, representing a broad range of realistic life histories (generation time from 1.1 to 265.6 years). Each selected population model defines the (st)age-specific demographic parameters in the mean environment, z= 0 (e.g., s1=0.2, s2=0.7, s3=0.85 and f3=0.5 at z= 0 in Fig. 1). We then simulated a stochastic environmental variable z and nonlinear functions with z for all survival probabilities and fertility coefficients in a population under 13 scenarios, varying the type of functions, the nature of buffered/labile demographic parameters and covariation among them (Fig. 2). For each population in each scenario, we calculated and decomposed the stochastic growth rate into nonlinearity and variance-covariance components.
We found that populations with short to intermediate generation times (<10 years) are the most responsive to environmental variability (positively or negatively), both through the nonlinearity and variance-covariance components. Interestingly, positive stochastic growth rate ln(λs) in these populations was detected in the majority of our scenarios, provided that survival and fertility covary negatively (Fig. 2). The positive effect of environmental variability results from i) a positive nonlinearity component due to convexity in fertility and survival responses, and ii) a reduced variance-covariance component due to negative covariation of the demographic parameters. The populations with shorter generation times have thus the largest potential for using demographic lability as an adaptive demographic response to environmental variability. In contrast, we detected only negative or weak positive nonlinearity component and weak negative variance-covariance component among populations with long generation times, leading to an overall slightly negative ln(λs) or a ln(λs) close to zero. This result indicates that demographic parameters are mostly buffered against environmental variability in these populations. Demographic buffering is thus a main adaptive demographic response to environmental variability for long-lived species.
 Figure 2 – Left panel: Illustration of one of the thirteen scenarios considered in our study. For each population, we simulated buffered survival rates of all mature stages (SMature), and labile survival rates of immature stages (SImmature) and fertilities fj(z) (through logistic functions) that covary negatively. The shape of the functions varied for each stage j depending on sj(z=0) and fj(z=0); but only one function is shown for survival and fertility here. Mid panel: Stochastic growth rate ln(λs) across generation time (in years; 154 populations). The sign of the stochastic growth rate directly reflects whether the effects of environmental variability in this scenario are positive or negative in that population. Right panel: Decomposition of ln(λs) into main components capturing variance-covariance effects (blue triangles; ‘variance-covariance component’) and lability effects generated by nonlinear responses of fj(z) (red circles) and sj(z) (orange circles; the sum of lability effects for a population corresponds to the ‘nonlinearity component’). The positive nonlinearity component arising from overall convexity in the responses of fertility and SImmature to z, overcomes the negative effect of the variance-component (reduced due to negative covariation of the demographic parameters and buffering of SMature).
Figure 2 – Left panel: Illustration of one of the thirteen scenarios considered in our study. For each population, we simulated buffered survival rates of all mature stages (SMature), and labile survival rates of immature stages (SImmature) and fertilities fj(z) (through logistic functions) that covary negatively. The shape of the functions varied for each stage j depending on sj(z=0) and fj(z=0); but only one function is shown for survival and fertility here. Mid panel: Stochastic growth rate ln(λs) across generation time (in years; 154 populations). The sign of the stochastic growth rate directly reflects whether the effects of environmental variability in this scenario are positive or negative in that population. Right panel: Decomposition of ln(λs) into main components capturing variance-covariance effects (blue triangles; ‘variance-covariance component’) and lability effects generated by nonlinear responses of fj(z) (red circles) and sj(z) (orange circles; the sum of lability effects for a population corresponds to the ‘nonlinearity component’). The positive nonlinearity component arising from overall convexity in the responses of fertility and SImmature to z, overcomes the negative effect of the variance-component (reduced due to negative covariation of the demographic parameters and buffering of SMature).
We hope this comprehensive framework to study how organisms adapt to environmental variability through demographic buffering and lability will help predicting (theoretically and empirically) population responses to changes in environmental fluctuations under climate change and other anthropogenic impacts.
Life history adaptations to fluctuating environments: Combined effects of demographic buffering and lability Christie Le Coeur, Nigel G. Yoccoz, Roberto Salguero-Gómez, Yngvild Vindenes https://onlinelibrary.wiley.com/doi/full/10.1111/ele.14071
Social Media
